Posted by Gal Beniamini, Project Zero
In this blog post we'll continue our journey into gaining remote kernel code execution, by means of Wi-Fi communication alone. Having previously developed a remote code execution exploit giving us control over Broadcom’s Wi-Fi SoC, we are now left with the task of exploiting this vantage point in order to further elevate our privileges into the kernel.

In this post, we’ll explore two distinct avenues for attacking the host operating system. In the first part, we’ll discover and exploit vulnerabilities in the communication protocols between the Wi-Fi firmware and the host, resulting in code execution within the kernel. Along the way, we’ll also observe a curious vulnerability which persisted until quite recently, using which attackers were able to directly attack the internal communication protocols without having to exploit the Wi-Fi SoC in the first place! In the second part, we’ll explore hardware design choices allowing the Wi-Fi SoC in its current configuration to fully control the host without requiring a vulnerability in the first place.
While the vulnerabilities discussed in the first part have been disclosed to Broadcom and are now fixed, the utilisation of hardware components remains as it is, and is currently not mitigated against. We hope that by publishing this research, mobile SoC manufacturers and driver vendors will be encouraged to create more secure designs, allowing a better degree of separation between the Wi-Fi SoC and the application processor.
Part 1 - The “Hard” Way
The Communication Channel
As we’ve established in the previous blog post, the Wi-Fi firmware produced by Broadcom is a FullMAC implementation. As such, it’s responsible for handling much of the complexity required for the implementation of 802.11 standards (including the majority of the MLME layer).
Yet, while many of the operations are encapsulated within the Wi-Fi chip’s firmware, some degree of control over the Wi-Fi state machine is required within the host’s operating system. Certain events cannot be handled solely by the Wi-Fi SoC, and must therefore be communicated to the host’s operating system. For example, the host must be notified of the results of a Wi-Fi scan in order to be able to present this information to the user.
In order to facilitate these cases where the host and the Wi-Fi SoC wish to communicate with one another, a special communication channel is required.
However, recall that Broadcom produces a wide range of Wi-Fi SoCs, which may be connected to the host via many different interfaces (including USB, SDIO or even PCIe). This means that relying on the underlying communication interface might require re-implementing the shared communication protocol for each of the supported channels -- quite a tedious task.

Perhaps there’s an easier way? Well, one thing we can always be certain of is that regardless of the communication channel used, the chip must be able to transmit received frames back to the host. Indeed, perhaps for the very same reason, Broadcom chose to piggyback on top of this channel in order to create the communication channel between the SoC and the host.
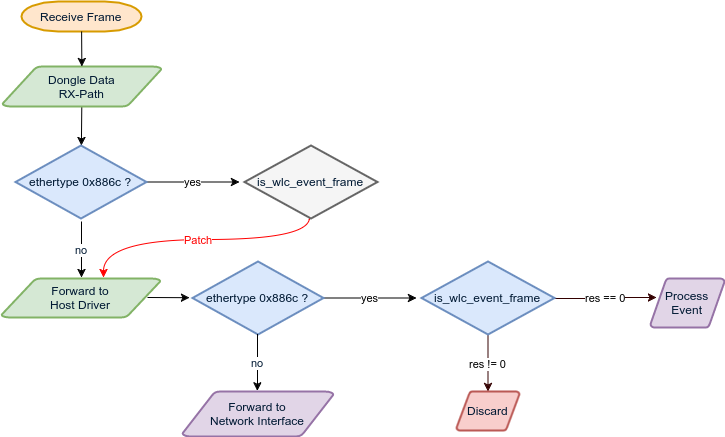
When the firmware wishes to notify the host of an event, it does so by simply encoding a “special” frame and transmitting it to the host. These frames are marked by a “unique” EtherType value of 0x886C. They do not contain actual received data, but rather encapsulate information about firmware events which must be handled by the host’s driver.

Securing the Channel
Now, let’s switch over the the host’s side. On the host, the driver can logically be divided into several layers. The lower layers deal with the communication interface itself (such as SDIO, PCIe, etc.) and whatever transmission protocol may be tied to it. The higher layers then deal with the reception of frames, and their subsequent processing (if necessary).

First, the upper layers perform some initial processing on the received frames, such as removing encapsulated data which may have been added on-top of it (for example, transmission power indicators added by the PHY module). Then, an important distinction must be made - is this a regular frame that should be simply forwarded to the relevant network interface, or is it in fact an encoded event that the host must handle?
As we’ve just seen, this distinction is easily made! Just take a look at the ethertype and check whether it has the “special” value of 0x886C. If so, handle the encapsulated event and discard the frame.
Or is it?
In fact, there is no guarantee that this ethertype is unused in every single network and by every single device. Incidentally, it seems that the very same ethertype is used for the LARQ protocol used in HPNA chips (initially developed by Epigram, and subsequently purchased by Broadcom).
Regardless of this little oddity - this brings us to our first question: how can the Wi-Fi SoC and host driver distinguish between externally received frames with the 0x886C ethertype (which should be forwarded to the network interface), and internally generated event frames (which should not be received from external sources)?
This is a crucial question; the internal event channel, as we’ll see shortly, is extremely powerful and provides a huge, mostly unaudited, attack surface. If attackers are able to inject frames over-the-air that can subsequently be processed as event frames by the driver, they may very well be able to achieve code execution within the host’s operating system.
Well… Until several months prior to this research (mid 2016), the firmware made no effort to filter these frames. Any frame received as part of the data RX-path, regardless of its ethertype, was simply forwarded blindly to the host. As a result, attackers were able to remotely send frames containing the special 0x886C ethertype, which were then processed by the driver as if they were event frames created by the firmware itself!
So how was this issue addressed? After all, we’ve already established that just filtering the ethertype itself is not sufficient. Observing the differences between the pre- and post- patched versions of the firmware reveals the answer: Broadcom went for a combined patch, targeting both the Wi-Fi SoC’s firmware and the host’s driver.
The patch adds a validation method (is_wlc_event_frame) both to the firmware’s RX path, and to the driver. On the chip’s side, the validation method is called immediately before transmitting a received frame to the host. If the validation method deems the frame to be an event frame, it is discarded. Otherwise, the frame is forwarded to the driver. Then, the driver calls the exact same verification method on received frames with the 0x886C ethertype, and processes them only if they pass the same validation method. Here is a short schematic detailing this flow:

As long as the validation methods in the driver and the firmware remain identical, externally received frames cannot be processed as events by the driver. So far so good.
However… Since we already have code-execution on the Wi-Fi SoC, we can simply “revert” the patch. All it takes is for us to “patch out” the validation method in the firmware, thereby causing any received frame to once again be forwarded blindly to the host. This, in turn, allows us to inject arbitrary messages into the communication protocol between the host and the Wi-Fi chip. Moreover, since the validation method is stored in RAM, and all of RAM is marked as RWX, this is as simple as writing “MOV R0, #0; BX LR” to the function’s prologue.
The Attack Surface
As we mentioned earlier, the attack surface exposed by the internal communication channel is huge. Tracing the control flow from the entry point for handling event frames (dhd_wl_host_event), we can see that several events receive “special treatment”, and are processed independently (see wl_host_event and wl_show_host_event). Once the initial treatment is done, the frames are inserted into a queue. Events are then dequeued by a kernel thread whose sole purpose is to read events from the queue and dispatch them to their corresponding handler function. This correlation is done by using the event’s internal “event-type” field as an index into an array of handler functions, called evt_handler.

While there are up to 144 different supported event codes, the host driver for Android, bcmdhd, only supports a much smaller subset of these. Nonetheless, about 35 events are supported within the driver, each including their own elaborate handlers.
Now that we’re convinced that the attack surface is large enough, we can start hunting for bugs! Unfortunately, it seems like the Wi-Fi chip is considered as “trusted”; as a result, some of the validations in the host’s driver are insufficient… Indeed, auditing the relevant handler functions and auxiliary protocol handlers outlined above, we find a substantial number of vulnerabilities.
The Vulnerability
Taking a closer look at the vulnerabilities we’ve found, we can see that they all differ from one another slightly. Some allow for relatively strong primitives, some weaker. However, most importantly, many of them have various preconditions which must be fulfilled to successfully trigger them; some are limited to certain physical interfaces, while others work only in certain configurations of the driver. Nonetheless, one vulnerability seems to be present in all versions of bcmdhd and in all configurations - if we can successfully exploit it, we should be set.
Let’s take a closer look at the event frame in question. Events of type "WLC_E_PFN_SWC" are used to indicate that a “Significant Wi-Fi Change” (SWC) has occurred within the firmware and must be handled by the host. Instead of directly handling these events, the host’s driver simply gathers all the transferred data from the firmware, and broadcasts a “vendor event” packet via Netlink to the cfg80211 layer.
More concretely, each SWC event frame transmitted by the firmware contains an array of events (of type wl_pfn_significant_net_t), a total count (total_count), and the number of events in the array (pkt_count). Since the total number of events can be quite large, it might not fit in a single frame (i.e., it might be larger than the the maximal MSDU). In this case, multiple SWC event frames can be sent consecutively - their internal data will be accumulated by the driver until the total count is reached, at which point the driver will process the entire list of events.

Reading through the driver’s code, we can see that when this event code is received, an initial handler is triggered in order to deal with the event. The handler then internally calls into the "dhd_handle_swc_evt" function in order to process the event's data. Let’s take a closer look:
1. void* dhd_handle_swc_evt(dhd_pub_t *dhd,const void *event_data,int *send_evt_bytes)
2. {
3. ...
4. wl_pfn_swc_results_t *results = (wl_pfn_swc_results_t *)event_data;
5. ...
6. gscan_params = &(_pno_state->pno_params_arr[INDEX_OF_GSCAN_PARAMS].params_gscan);
7. params = &(gscan_params->param_significant);
8. ...
9. if (!params->results_rxed_so_far) {
10. if (!params->change_array) {
11. params->change_array = (wl_pfn_significant_net_t *)
12. kmalloc(sizeof(wl_pfn_significant_net_t) *
8. ...
9. if (!params->results_rxed_so_far) {
10. if (!params->change_array) {
11. params->change_array = (wl_pfn_significant_net_t *)
12. kmalloc(sizeof(wl_pfn_significant_net_t) *
13. results->total_count, GFP_KERNEL);
14. ...
15. }
16. }
17. ...
18. change_array = ¶ms->change_array[params->results_rxed_so_far];
19. memcpy(change_array,
14. ...
15. }
16. }
17. ...
18. change_array = ¶ms->change_array[params->results_rxed_so_far];
19. memcpy(change_array,
20. results->list,
21. sizeof(wl_pfn_significant_net_t) * results->pkt_count);
22. params->results_rxed_so_far += results->pkt_count;
23. ...
24. }
22. params->results_rxed_so_far += results->pkt_count;
23. ...
24. }
(where "event_data" is the arbitrary data encapsulated in the event passed in from the firmware)
As we can see above, the function first allocates an array to hold the total count of events (if one hasn’t been allocated before) and then proceeds to concatenate the encapsulated data starting from the appropriate index (results_rxed_so_far) in the buffer.
However, the handler fails to verify the relation between the total_count and the pkt_count! It simply “trusts” the assertion that the total_count is sufficiently large to store all the subsequent events passed in. As a result, an attacker with the ability to inject arbitrary event frames can specify a small total_count and a larger pkt_count, thereby triggering a simple kernel heap overflow.
Remote Kernel Heap Shaping
This is all well and good, but how can we leverage this primitive from a remote vantage point? As we’re not locally present on the device, we’re unable to gather any data about the current state of the heap, nor do we have address-space related information (unless, of course, we’re able to somehow leak this information). Many classic exploits targeting kernel heap overflows rely on the ability to shape the kernel’s heap, ensuring a certain state prior to triggering an overflow - an ability we also lack at the moment.
What do we know about the allocator itself? There are a few possible underlying implementations for the kmalloc allocator (SLAB, SLUB, SLOB), configurable when building the kernel. However, on the vast majority of devices, kmalloc uses “SLUB” - an unqueued “slab allocator” with per-CPU caches.
Each “slab” is simply a small region from which identically-sized allocations are carved. The first chunk in each slab contains its metadata (such as the slab’s freelist), and subsequent blocks contain the allocations themselves, with no inline metadata. There are a number of predefined slab size-classes which are used by kmalloc, typically spanning from as little as 64 bytes, to around 8KB. Unsurprisingly, the allocator uses the best-fitting slab (smallest slab that is large enough) for each allocation. Lastly, the slabs’ freelists are consumed linearly - consecutive allocations occupy consecutive memory addresses. However, if objects are freed within the slab, it may become fragmented - causing subsequent allocations to fill-in “holes” within the slab instead of proceeding linearly.

With this in mind, let’s take a step back and analyse the primitives at hand. First, since we are able to arbitrarily specify any value in total_count, we can choose the overflown buffer’s size to be any multiple of sizeof(wl_pfn_significant_net). This means we can inhabit any slab cache size of our choosing. As such, there’s no limitation on the size of the objects we can target with the overflow. However, this is not quite enough… For starters, we still don’t know anything about the current state of the slabs themselves, nor can we trigger remote allocations in slabs of our choosing.
It seems that first and foremost, we need to find a way to remotely shape slabs. Recall, however, that there are a few obstacles we need to overcome. As SLUB maintains per-CPU caches, the affinity of the kernel thread in which the allocation is performed must be the same as the one from which the overflown buffer is allocated. Gaining a heap shaping primitive on a different CPU core will cause the allocations to be taken from different slabs. The most straightforward way to tackle this issue is to confine ourselves to heap shaping primitives which can be triggered from the same kernel thread on which the overflow occurs. This is quite a substantial constraint… In essence, it forces us to disregard allocations that occur as a result of processes that are external to the event handling itself.
Regardless, with a concrete goal in mind, we can start looking for heap shaping primitives in the registered handlers for each of the event frames. As luck would have it, after going through every handler, we come across a (single) perfect fit!
Events frames of type “WLC_E_PFN_BSSID_NET_FOUND” are handled by the handler function dhd_handle_hotlist_scan_evt. This function accumulates a linked list of scan results. Every time an event is received, its data is appended to the list. Finally, when an event arrives with a flag indicating it is the last event in the chain, the function passes on the collected list of events to be processed. Let’s take a closer look:
1. void *dhd_handle_hotlist_scan_evt(dhd_pub_t *dhd, const void *event_data,
2. int *send_evt_bytes, hotlist_type_t type)
3. {
4. struct dhd_pno_gscan_params *gscan_params;
5. wl_pfn_scanresults_t *results = (wl_pfn_scanresults_t *)event_data;
6. gscan_params = &(_pno_state->pno_params_arr[INDEX_OF_GSCAN_PARAMS].params_gscan);
7. ...
8. malloc_size = sizeof(gscan_results_cache_t) +
9. ((results->count - 1) * sizeof(wifi_gscan_result_t));
10. gscan_hotlist_cache = (gscan_results_cache_t *) kmalloc(malloc_size, GFP_KERNEL);
11. ...
12. gscan_hotlist_cache->next = gscan_params->gscan_hotlist_found;
13. gscan_params->gscan_hotlist_found = gscan_hotlist_cache;
14. ...
15. gscan_hotlist_cache->tot_count = results->count;
16. gscan_hotlist_cache->tot_consumed = 0;
17. plnetinfo = results->netinfo;
18. for (i = 0; i < results->count; i++, plnetinfo++) {
19 hotlist_found_array = &gscan_hotlist_cache->results[i];
20. ... //Populate the entry with the sanitised network information
21. }
22. if (results->status == PFN_COMPLETE) {
23. ... //Process the entire chain
24. }
25. ...
26.}
Awesome - looking at the function above, it seems that we’re able to repeatedly cause allocations of size { sizeof(gscan_results_cache_t) + (N-1) * sizeof(wifi_gscan_result_t) | N > 0 } (where N denotes results->count). What’s more, these allocations are performed in the same kernel thread, and their lifetime is completely controlled by us! As long as we don’t send an event with the PFN_COMPLETE status, none of the allocations will be freed.
Before we move on, we’ll need to choose a target slab size. Ideally, we’re looking for a slab that’s relatively inactive. If other threads on the same CPU choose to allocate (or free) data from the same slab, this would add uncertainty to the slab’s state and may prevent us from successfully shaping it. After looking at /proc/slabinfo and tracing kmalloc allocations for every slab with the same affinity as our target kernel thread, it seems that the kmalloc-1024 slab is mostly inactive. As such, we’ll choose to target this slab size in our exploit.
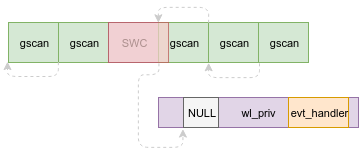
By using the heap shaping primitive above we can start filling slabs of any given size with “gscan” objects. Each “gscan” object has a short header containing some metadata relating to the scan and a pointer to the next element in the linked list. The rest of the object is then populated by an inline array of “scan results”, carrying the actual data for this node.

Going back to the issue at hand - how can we use this primitive to craft a predictable layout?
Well, by combining the heap shaping primitive with the overflow primitive, we should be able to properly shape slabs of any size-class prior to triggering the overflow. Recall the initially any given slab may be fragmented, like so:

However, after triggering enough allocations (e.g. (SLAB_TOTAL_SIZE / SLAB_OBJECT_SIZE) - 1) with our heap shaping primitive, all the holes (if present) in the current slab should get populated, causing subsequent allocations of the same size-class to be placed consecutively.

Now, we can send a single crafted SWC event frame, indicating a total_count resulting in an allocation from the same target slab. However, we don’t want to trigger the overflow yet! We still have to shape the current slab before we do so. To prevent the overflow from occurring, we’ll provide a small pkt_count, thereby only partially filling in the buffer.

Finally, using the heap shaping primitive once again, we can fill the rest of the slab with more of our “gscan” objects, bringing us to the following heap state:

Okay… We’re getting there! As we can see above, if we choose to use the overflow primitive at this point, we could overwrite the contents of one of the “gscan” objects with our own arbitrary data. However, we’ve yet to determine exactly what kind of result that would yield…
Analysing The Constraints
In order to determine the effect of overwriting a “gscan” object, let’s take a closer look at the flow that processes a chain of “gscan” objects (that is, the operations performed after an event with a “completion” flag is received). This processing is handled by wl_cfgvendor_send_hotlist_event. The function goes over each of the events in the list, packs the event’s data into an SKB, and subsequently broadcasts the SKB over Netlink to any potential listeners.
However, the function does have a certain obstacle it needs to overcome; any given “gscan” node may be larger than the maximal size of an SKB. Therefore, the node would need to be split into several SKBs. To keep track of this information, the “tot_count” and “tot_consumed” fields in the “gscan” structure are utilised. The “tot_count” field indicates the total number of embedded scan result entries in the node’s inline array, and the “tot_consumed” field indicates the number of entries consumed (transmitted) so far.
As a result, the function slightly modifies the contents of the list while processing it. Essentially, it enforces the invariant that each processed node’s “total_consumed” field will be modified to match its “tot_count” field. As for the data being transmitted and how it’s packed, we’ll skip those details for brevity’s sake. However, it’s important to note that other than the aforementioned side effect, the function above appears to be quite harmless (that is, no further primitives can be “mined” from it). Lastly, after all the events are packed into SKBs and transmitted to any listeners, they can finally be reclaimed. This is achieved by simply walking over the list, and calling “kfree” on each entry.
Putting it all together, where does this leave us with regards to exploitation? Assuming we choose to overwrite one of the “gscan” entries using the overflow primitive, we can modify its “next” field (or rather, must, as it is the first field in the structure) and point it at any arbitrary address. This would cause the processing function to use this arbitrary pointer as if it were an element in the list.

Due to the invariant of the processing function - after processing the crafted entry, its 7th byte (“tot_consumed”) will be modified to match its 6th byte (“tot_count”). In addition, the pointer will then be kfree-d after processing the chain. What’s more, recall that the processing function iterates over the entire list of entries. This means that the first four bytes in the crafted entry (its “next” field) must either point to another memory location containing a “valid” list node (which must then satisfy the same constraints), or must otherwise hold the value 0 (NULL), indicating that this is the last element in the list.
This doesn’t look easy… There’s quite a large number of constraints we need to consider. If we willfully choose the ignore the kfree for a moment, we could try and search for memory locations where the first four bytes are zero, and where it would be beneficial to modify the 7th byte to match the 6th. Of course, this is just the tip of the iceberg; we could repeatedly trigger the same primitive in order to repeatedly copy bytes one position to the left. Perhaps, if we were able to locate a memory address where enough zero bytes and enough bytes of our choosing are present, we could craft a target value by consecutively using these two primitives.
In order to gage the feasibility of this approach, I’ve encoded the constraints above in a small SMT instance (using Z3), and supplied the actual heap data from the kernel, along with various target values and their corresponding locations. Additionally, since the kernel’s translation table is stored at a constant address in the kernel’s VAS and even slight modifications to it can result in exploitable conditions, its contents (along with corresponding target values) was added to the SMT instance as well. The instance was constructed to be satisfiable if and only if any of the target values could occupy any of the target locations within no more than ten “steps” (where each step is an invocation of the primitive). Unfortunately, the results were quite grim… It seemed like this approach just wasn’t powerful enough.
Moreover, while this idea might be nice in theory, it doesn’t quite work in practice. You see, calling kfree on an arbitrary address is not without side-effects of its own. For starters, the page containing the memory address must be marked as either a “slab” page, or as “compound”. This only holds true (in general) for pages actually used by the slab allocator. Trying to call kfree on an address in a page that isn’t marked as such, triggers a kernel panic (thereby crashing the device).
Perhaps, instead, we can choose to ignore the other constraints and focus on the kfree? Indeed, if we are able to consistently locate an allocation whose data can be used for the purpose of the exploit, we could attempt to free that memory address, and then “re-capture” it by using our heap shaping primitive. However, this raises several additional questions. First, will we be able to consistently locate a slab-resident address? Second, even if we were to find such an address, surely it will be associated with a per-CPU cache, meaning that freeing it will not necessarily allow us to reclaim it later on. Lastly, whichever allocation we do choose to target, will have to satisfy the constraints above - that is, the first four bytes must be zero, and the 7th byte will be modified to match the 6th.
However, this is where some slight trickery comes in handy! Recall that kmalloc holds a number of fixed-size caches. Yet what should happen when a larger allocation is requested? In turn out that in that case, kmalloc simply returns a number of consecutive free pages (using __get_free_pages) and returns them to the caller. This is done without any per-CPU caching. As such, if we are able to free a large allocation, we should then be able to reclaim it without having to consider which CPU allocated it in the first place.
This may solve the problem of affinity, but it still doesn’t help us locate these allocations. Unfortunately, the slab caches are allocated quite late in the kernel’s boot process, and their contents are very “noisy”. This means that even guessing a single address within a slab is quite difficult, even more so for remote attackers. However, early allocations which use the large allocation flow (that is, which are created using __get_free_pages) do consistently inhabit the same memory addresses! This is as long as they occur early enough during the kernel’s initialisation so that no non-deterministic events happen concurrently.
Combining these two facts, we can search for a large early allocation. After tracing the large allocation path and rebooting the kernel, it seems that there are indeed quite a few such allocations. To help navigate this large trace, we can also compile the Linux kernel with a special GCC plugin that outputs the size of each structure used in the kernel. Using these two traces, we can quickly navigate the early large allocations, and try and search for a potential match.
After going over the list, we come across one seemingly interesting entry:

Putting It All Together
During the bcmdhd driver’s initialisation, it calls the wiphy_new function in order to allocate an instance of wl_priv. This instance is used to hold much of the metadata related to the driver’s operation. But there’s one more sneaky little piece of data hiding within this structure - the event handler function pointer array used to handle incoming event frames! Indeed, the very same table we were discussing earlier on (evt_handler), is stored within this object. This leads us to a direct path for exploitation - simply kfree this object, then send an SWC event frame to reclaim it, and fill it with our own arbitrary data.
Before we can do so, however, we’ll need to make sure that the object satisfies the constraints mandated by the processing function. Namely, the first four bytes must be zero, and we must be able to modify the 7th byte to match the value of the 6th byte. While the second constraint poses no issue at all, the first constraint turns out to be quite problematic! As it happens, the first four bytes are not zero, but in fact point to a block of function pointers related to the driver. Does this mean we can’t use this object after all?
No - as luck would have it, we can still use one more trick! It turns out that when kfree-ing a large allocation, the code path for kfree doesn’t require the passed in pointer to point to the beginning of the allocation. Instead, it simply fetches the pages corresponding to the allocation, and frees them instead. This means that by specifying an address located within the structure that does match the constraints, we’ll be able to both satisfy the requirements imposed by the processing function and free the underlying object. Great.
Putting this all together, we can now simply send along a SWC event frame in order to reclaim the evt_handler function pointer array, and populate it with our own contents. As there is no KASLR, we can search for a stack pivot gadget in the kernel image that will allow us to gain code execution. For the purpose of the exploit, I’ve chosen to replace the event handler for WLC_E_SET_SSID with a stack pivot into the event frame itself (which is stored in R2 when the event handler is executed). Lastly, by placing a ROP stack in a crafted event frame of type WLC_E_SET_SSID, we can now gain control over the kernel thread’s execution, thus completing our exploit.

You can find a sample exploit for this vulnerability here. It includes a short ROP chain that simply calls printk. The exploit was built against a Nexus 5 with a custom kernel version. In order to modify it to work against different kernel versions, you’ll need to fill in the appropriate symbols (under symbols.py). Moreover, while the primitives are still present in 64-bit devices, there might be additional work required in order to adjust the exploit for those platforms.
With that, let’s move on to the second part of the blog post!
Part 2 - The “Easy” Way
How Low Can You Go?
Although we’ve seen that the high-level communication protocols between the Wi-Fi firmware and the host may be compromised, we’ve also seen how tedious it might be to write a fully-functional exploit. Indeed, the exploit detailed above required sufficient information about the device being targeted (such as symbols). Furthermore, any mistake during the exploitation might cause the kernel to crash; thereby rebooting the device and requiring us to start all over again. This fact, coupled with our transient control over the Wi-Fi SoC, makes these types of exploit chains harder to exploit reliably.
That said, up until now we’ve only considered the high-level attack surface exposed to the firmware. In effect, we were thinking of the Wi-Fi SoC and the application processor as two distinct entities which are completely isolated from one another. In reality, we know that nothing can be further from the truth. Not only are the Wi-Fi SoC and the host physically proximate to one another, they also share a physical communication interface.
As we’ve seen before, Broadcom manufactures SoCs that support various interfaces, including SDIO, USB and even PCIe. While the SDIO interface used to be quite popular, in recent years it has fallen out of favour in mobile devices. The main reason for the “disappearance” of SDIO is due to its limited transfer speeds. As an example, Broadcom’s BCM4339 SoC supports SDIO 3.0, a fairly advanced version of SDIO. Nonetheless, it is still limited to a theoretical maximal bus speed of 104 MB/s. On the other hand, 802.11ac has a theoretical maximal speed of 166 MB/s - much more than SDIO can cope with.
 BCM4339 Block Diagram
BCM4339 Block Diagram









Wow, that wasn't easy!
ReplyDeleteAmazing.
ReplyDeleteIs brcmfmac vulnerable to the same or similar exploit?
ReplyDeleteIs brcmfmac vulnerable to the same or similar attack?
ReplyDeleteThat's fun!
ReplyDeleteWould this also apply to the wifi routers that use the broadcom chips and drivers?
ReplyDeleteThe firmware bugs we found were only relevant to the client-related logic, so I don't believe they apply to routers. As for the driver bugs - they were in Android's driver, so I'm pretty sure they don't apply to routers either.
DeleteGreat fun! Like writing bootstrap code...
ReplyDeleteIf I was 50 years younger, this would be my hobby!
Incredible and I mean incredible article! Really enjoyed and did require some repeptive paragraph reading on my part.
ReplyDeleteLots of very intersting take aways but the overloading of ethertype was one of the most fascinating. Not to be too conspiracy minded but what an easy backdoor to leave. Would be so easy to use later and not obvious. Easy deniability.
Hmm... trying to understand this piece of greatness but my System.Map doesn't contain any of the symbols used in rdev.py and therefore throws an error when trying to run the poc.
ReplyDeleteThe System.map needs to correspond to the kernel for the hammerhead on which you're running the exploit. You can also dump /proc/kallsyms and rename it to System.map. Note that there are other symbols you'll need to extract on your own (see symbols.py).
Deletehmm... trying to understand this piece of greatness but my System.Map doesn't contain any of the symbols used in rdev.py and therefore crashes when trying to run the poc.
ReplyDeleteGiven the theme of this blog, it might be reasonable to provide an email addy to "pitch something over the transom" rather than appear as an open comment.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteAnd yet, Google will not patch the vulnerability on Nexus 5 devices.
ReplyDeleteHi! For the 'dhd_handle_swc_evt' Heap Overflow, should we also need the patches you mentioned in your first part? ("Regrettably, however, mac80211 is unable to process the special vendor frames, and simply rejects them. Nonetheless, this is just a minor inconvenience - I’ve written a few patches to mac80211 which add support for these special vendor frames. After applying these patches, re-compiling and booting the kernel, we are now able to send our crafted frames.")
ReplyDeleteIf so, what patches do we need here to realize the 'dhd_handle_swc_evt' Heap Overflow? Thanks!!!
No. The patches for mac80211 were only needed on the attacker's side in order to allow mac80211 to send the crafted vendor frames used in the TDLS exploit.
Delete